
Är du nyfiken på hur Boolis värderingar fungerar mer ingående? Då har du hittat rätt. Här går vi igenom allt ifrån hur det går till när vi tar fram en värdering till vad som händer om marknaden förändras. Vi lyfter också upp vilka styrkor och svagheter som finns. En värdefull fördjupning helt enkelt!
För att Booli ska kunna värdera en bostad behöver vi först samla in information om bostaden. Det kan till exempel vara adress, bo- och biarea, antal rum och eventuell tomtstorlek. Vi använder sen den informationen för att hitta liknande försäljningar i närområdet som vi baserar värderingen på. Därefter använder vi oss av olika modeller, bland annat med hjälp av AI, för att göra en så träffsäker värdering som möjligt.
📍Positionering och beskrivning av bostaden
Steg ett i en värdering är att ange var bostaden ligger. Utifrån en adress får vi fram en koordinat som beskriver var i Sverige bostaden finns. Därefter samlar vi in beskrivande information som bo- och biarea, tomtarea, antal rum, bostadstyp, ägandeform, avgift till förening, driftskostnad, taxeringsvärde, standardpoäng, vatten, avlopp, byggår, bergvärmepump, balkong och brf-data som exempelvis föreningens belåningsgrad osv.
Exakt vilka attribut vi använder beror på vilken sorts bostad det är och vilken ägandeform den har. Ibland är inte all information tillgänglig för en bostad och då använder vi den mängd vi har tillgång till.
För vissa datapunkter, som taxeringsvärde, standardpoäng, vatten och avlopp får vi inte informationen via värderingsformuläret. Vi använder istället data från Lantmäteriet.
⚖️ Val av värderingsmodeller baserat på boendeform och ägandeform
Värderingsmodellen består av flera olika modeller:
- En basmodell som värderar baserat på liknande försäljningar i området
- En boosting-modell som använder data om de tidigare försäljningarna i basmodellen
- En modell som baseras på tidigare försäljning av samma bostad
- Samt en skicksmodell som justerar värdet och som baseras på data angiven av användare som endast används för privata värdebevakningar.
Basmodellen och boosting-modellen används för alla värderingar. Modellen som värderar utifrån tidigare försäljningar används bara i de fall vi har information om en tidigare försäljning av samma bostad. För villor och radhus kan vi ofta hitta sådana försäljningar baserat på enbart adressen, men för lägenheter behöver vi ha tillgång till lägenhetsnumret.
Basmodellen är i sin tur uppdelad i fyra olika delmodeller som alla fungerar på samma sätt men som är tränade för olika bostadstyper.
Vi delar upp den i en villamodell, en lägenhetsmodell, en modell för radhus som bostadsrätt och en sista modell för radhus som äganderätt. Parhus och kedjehus grupperas tillsammans med radhusen.

🏘Värdering baserat på liknande försäljningar
Vår basmodell för värdering använder en maskininlärningsteknik som kallas kernel regression, och vi använder en generisk algoritm för att träna den. Kernel regression har stora likheter med K-nearest neighbours (k-NN) men har vissa signifikanta fördelar som gör att den presterar bättre.
Båda teknikerna uppskattar ett förväntat slutpris på en osåld bostad genom att ta ett viktat medelvärde av slutpriserna för liknande sålda bostäder. Den här metodiken påminner mycket om hur man gör en manuell värdering, alltså genom att samla in information om tidigare försäljningar och göra en skattning baserat på det.
1. Insamling av liknande försäljningar
Första steget i basmodellens värdering är att samla in potentiella referensförsäljningar. Och vi samlar in fler jämförelser än många kanske tror. Vi utgår från koordinaten för bostaden vi vill värdera och hämtar in information om de 1000 geografiskt närmsta försäljningarna vi kan hitta. Genom att ta de 1000 närmsta får vi ett underlag som anpassar sig efter försäljningstäthet och omsättning i området.

I storstäder kommer vi få en cirkel av referensförsäljningar som är ganska liten, medan den i glesbygd kan bli väldigt stor. Vi har gjort flera försök att dela upp landet i olika delområden baserat på bland annat län, kommun, stadsdel, DeSO och församling. Men vi har sett att den här “automatiska” anpassningen av upptagningsområdet presterar bättre än områdesindelningar och gränsdragningar.
2. Likhetsbedömning
Efter att vi hämtat upp 1000 försäljningar i närområdet gör vi en bedömning av hur lika de är bostaden vi vill värdera. Utifrån attributen som beskriver bostäderna (bo- och biarea, antal rum, taxeringsvärde, m.m.) samt med hänsyn till hur länge sedan en försäljning skedde och hur långt bort den ligger, görs en bedömning av hur lika de är värderingsbostaden.
Om vi hittar en referensförsäljning på samma adress som värderingsbostaden från förra veckan med identisk boarea kommer den försäljningen troligtvis ges ett högt värde på likhet.
En referensförsäljning från flera år sedan, som ligger långt bort och/eller på andra sätt har stora olikheter med värderingsbostaden kommer ges ett lågt likhetsvärde. De olika attribut vi tar hänsyn till har alltså olika vikt i bedömningen, och dessa vikter tränas fram med AI för att ge så bra värderingsresultat som möjligt.
3. Indexjustering av slutpriser
Nästa steg i basmodellen är att indexjustera försäljningspriserna för de funna referensförsäljningarna. Att indexjustera innebär kortfattat att justera äldre slutpriser till dagens prisnivåer, för att kunna göra en mer rättvis jämförelse.
Vi använder SBAB Booli Housing Price Index för det indexområde som värderingsbostaden ligger i och räknar upp eller ned priserna på alla referensförsäljningar enligt index. På så sätt får vi en indikation på vad referensobjekten hade sålts för på dagens marknad.

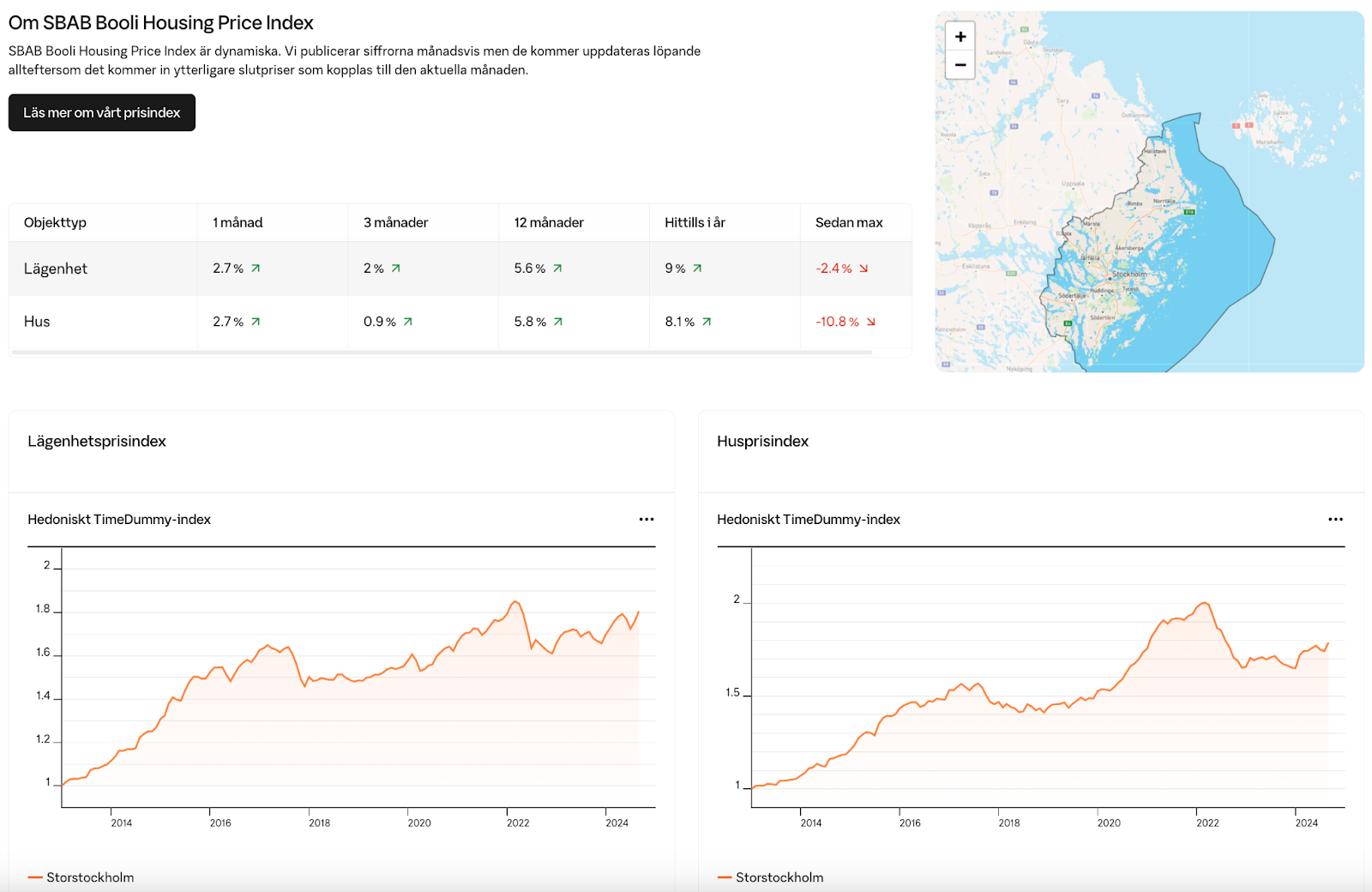
Denna indexjustering är anledningen till att en värdering kan förändras över tid, trots att det inte säljs något i närheten. Vi tar på det sättet in indexområdets generella prisförändring i alla värderingar, även i de delar av landet som har väldigt låg omsättning. Våra utvärderingar visar att detta ger en markant förbättring av precisionen i värderingarna.
4. Sammanviktning av slutpriser baserat på likhet
När vi har ett likhetsvärde och ett aktuellt slutpris för samtliga 1000 referensförsäljningar kan vi beräkna ett viktat medelvärde, där vikten ges av hur lik referensförsäljningen är värderingsobjektet.
Att ta ett viktat medelvärde innebär att man tar ett snitt av priserna, där den påverkan varje pris får är styrt av hur betydelsefull den är för värderingen. Det kan låta mycket att ta hänsyn till 1000 referensobjekt, men oftast kommer endast ett fåtal ha en signifikant inverkan på värderingen.
Likhetsmåttet beräknas genom att vi har en snabbt avklingande fördelning av likhetsvärden på referensobjekten. För bostäder där det endast finns ett fåtal lika objekt i närområdet (t.ex. en villa på landet eller en unik lägenhet i staden) kommer de fåtalet ges en stor vikt vid värderingen. För bostäder där det finns många liknande referensobjekt (t.ex. en lägenhet i närförort eller ett radhus i ett radhusområde) kommer fler objekt kunna ge påverkan på värderingen.
5. Efterjustering baserat på andra attribut
Efter att vi beräknat det viktade medelvärdet som är basen för värderingen gör vi en efterhandsjustering baserat på våningsplan och balkong (för lägenheter) och bergvärmepump (villa).
I fallet med våningsplan har vi sett att våningen har en stor påverkan på priset för en lägenhet – högt upp i huset ger oftast ett högre pris än långt ner i huset. Men när vi tar med våningsplanet i likhetsbedömningen enligt ovan har det visat sig ge en försämring i värderingarnas precision. Därför har vi istället valt att justera upp eller ned värderingen baserat på hur värderingsbostadens våningsplan skiljer sig från referensobjektens våningsplan.

🏘 Värdering baserat på boosting-modell
Boosting är en ensemble modell inom machine learning som viktar ihop många simpla modeller. Vi använder en variant av boosting som består av beslutsträd. Datan den får är bl.a. information om objektet såsom boarea, byggår, taxeringsvärde. Men den får även basvärderingen och data från tidigare försäljningar.
🏘 Värdering baserat på tidigare försäljning av samma bostad
Om vi kan se att samma bostad har sålts tidigare beräknar vi ett aktuellt värde på den tidigare försäljningen med hjälp av prisindex. Vi ger sedan det värdet en vikt baserat på hur länge sedan försäljningen skedde, och viktar på så sätt in den i värderingen som presenteras för dig som användare. En försäljning som skedde nära i tid kommer ge större påverkan än en som skedde för en längre tid sedan.
🏘 Värdering baserat på skicksparametrar
Om användaren har angett skicksparametrar i vårt värderingsformulär (exempelvis skick i kök och badrum, utsikt, solceller och uppvärmningskälla) så gör vi slutligen en justering baserat på dessa.
Justeringen är baserad på analyser vi har gjort om hur olika skicksparametrar påverkar slutpriset. Denna justering görs med en regressionsmodell som är specialtränad för olika områden och objekttyper.
⚖️ Hur träffsäkra är Boolis värderingar?
För att bedöma precisionen på värderingarna så jämför vi dem med faktiska försäljningspriser. Booli samlar in försäljningsdata löpande och gör utvärderingar där vi varje vecka jämför vår värdering av en bostad med priset den såldes för.
För lägenheter i storstäder hamnar majoriteten av Boolis värderingar inom 6 % från det pris de säljs för. För småhus hamnar majoriteten av värderingarna inom 9 % från slutpriset. Medianfelet ligger kring +/- 0,5 % under stabila marknadslägen. Det gör Boolis värderingar till de mest träffsäkra statistiska värderingarna i Sverige.

🔍Styrkor och svagheter med Boolis statistiska värderingar
✋Svagheter
En statistisk värdering är helt beroende av att datan vi har är korrekt, och så är tyvärr inte alltid fallet. Boolis data håller generellt väldigt hög kvalitet, men perfekt data är omöjlig att uppnå och det kommer alltid finnas vissa felaktigheter. Felaktigheterna kan komma från att data matats in på felaktigt sätt i mäklarsystem eller hos Lantmäteriet, eller att våra automatiserade insamlingssystem tolkar datan på fel sätt.
Det finns också fall av medvetet vilseledande data. Till exempel är det inte ovanligt att villor är feltaxerade, exempelvis genom att fel boarea är angiven till Skatteverket/Lantmäteriet, och att informationen vi får från Lantmäteriet inte alltid stämmer överens med informationen som står i mäklarannonsen. I det fallet låter vi informationen i annonsen ha företräde då vi utgår från att den speglar sanningen bättre. Men vi är beroende av taxeringsvärdet från Lantmäteriet för att göra en bra värdering och om taxeringsvärdet i dessa fall är felaktigt så introducerar detta en felkälla i likhetsbedömningen.

En annan svaghet med en databaserad värderingsmetod är att all information om en bostad inte går att beskriva med siffror. Eller att datan inte går, eller är väldigt svår, att få tag på. Attribut som ljusinsläpp, bullernivå och utsikt som teoretiskt skulle gå att kvantifiera kan vi inte ta hänsyn till då datan inte är tillgänglig för oss.
Databaserade modeller ställer också krav på att data ska finnas i tillräckliga volymer för att de ska vara pålitliga. Vi stöter ibland på önskemål om att kunna vara mer specifika i de prisindex vi använder, till exempel kan vi få förfrågningar om ett prisindex specifikt för Midsommarkransen eller något annat mindre område. Många ser prisindexområdena som för stora och ställer sig frågan om inte prisutvecklingen i just deras område skiljer sig från övriga områden. Tyvärr kräver prisindex en väldigt stor mängd försäljningar för att kunna beräknas tillförlitligt och därför är det inte möjligt att beräkna ett rättvisande index i områden där omsättningen är för liten.
När man som användare tolkar en värdering behöver man också ha rätt förväntningar på precisionen. Vi använder slutpriset som facit i våra utvärderingar och slutpriser speglar inte alltid det “korrekta” marknadsvärdet. Det händer att bostäder säljs både lite för dyrt och lite för billigt i förhållande till deras verkliga värde. Det finns alltså en viss brusighet i den data vi använder som underlag för att träna vår modell. Därför anser vi att en värdering som hamnar inom +/- 5 % från slutpriset är en korrekt värdering.
💪Styrkor
Styrkorna med vår statistiska modell är bland annat att det möjliggör för oss att värdera hela Sveriges bostadsbestånd, en gång i veckan året om, och tillgängliggöra den informationen på Booli. Det är vi ensamma om att göra.
För oss är transparens viktigt. Vi gör information tillgänglig som tidigare varit reserverad för mäklare och bolåneinstitut och ger på så sätt möjlighet för privatpersoner att ta bättre, mer välgrundade beslut i sina bostadsaffärer.
Genom att publicera slutpriser och värderingar, samt ge tillgång till ett gratis värderingsverktyg gör Booli bostadsmarknaden mer transparent. Samtidigt skapar vi jämlikare villkor för köpare och säljare, så att mäklarna får ett mindre informationsövertag.
Vi gör dessutom detta med en modell som visat sig vara Sveriges bästa statistiska värderingsmodell för lägenheter och småhus.
👋 Här syns värderingen
Vi visar värderingen som ett ungefärligt värde på sista sidan i värderingsformuläret, och på Mitt Booli när du är inloggad.
På Mitt Booli presenteras värderingen tillsammans med en graf som värdeförändringen över tid. Grafen bygger på det nuvarande värdet justerat bakåt i tiden med prisindex, och visar därför inte faktiska historiska värderingar. Vi använder denna metod eftersom vi anser att den aktuella värderingen är den mest exakta, då den bygger på mest information. En indexjusterad versionav den ger därför en mer pålitlig bild av värdeutvecklingen över tid.
Dessutom visar vi en värdering på nästan alla bostadsobjekt på Booli, även på bostäder som inte är till salu. Dessa värderingar påverkas inte av data från värderingsformuläret utan är enbart baserade på data som vi redan har om bostaden.


